
BT(0) - B树
B 树是波音实验室的 Rudolf Bayer and Edward M. McCreight 最初发明用来存储大量索引(超过主内存)的数据结构,在 1970 年的论文里正式提出。
本系列将介绍 B 树以及 B+ 树、B+ 树的 TreeMap 实现、 B+* 树等一些列算是 B 树的变种。
概念基础
B 树是完全平衡的多路搜索树,基本上已经是传统红黑树的上位替代。
- 节点数的减少,极大地节省了内存;
- 在大缓存 CPU 架构下,性能明显高于传统二叉搜索树
完全平衡指得是每个叶子节点到根节点的深度相等。
B 树节点一般可以分为最后一层的叶子节点(leaf)和中间的节点(internal),当B 树只有一层的时候,那就只有叶子节点。
对于 $m$ 阶 B 树(最多有 $m$ 个孩子)有这样的性质:
- 中间节点的键数 $N_{\large\text{key}} \in [\lceil {\large\frac{m}{2}}\rceil-1,m)$
- 叶子节点的键数 $N_{\large\text{key}} \in [1,m)$
其中根节点比较特殊,对于高度大于 $1$ 的 B 树,根节点显然属于是中间节点,但它可以像叶子节点一样最少只有单键1。因此一些介绍里把 internal 节点的概念定义为不包括根节点,而另外的介绍里则保留这种矛盾,这是让初学者很困惑的一个地方。
而中间节点的最小键数 $\lceil {\large\frac{m}{2}}\rceil-1$ ,是由一个溢出节点的分裂过程推导出的:
假设一个节点溢出了,则此时它有 $m$ 个键,此时应该取出中间的一个键,推到父节点上,然后把左右两边的键平分为两个节点。这种情况下 $\lceil{\large\frac{m}{2}}\rceil + \lceil{\large\frac{m}{2}}\rceil - 2 = m + 1 - 2 = m - 1$ 。
并且显然,应该有 $m \geqslant 3$ ,二叉树一个节点里只有一个键,没有节点分裂与合并的空间。
重平衡
我们把对插入时节点键值溢出和删除时节点键值不足的情况的处理操作,按照前文二叉搜索树的惯例,也一样地称之为重平衡。
文字说明未必直观,可以通过在线的 B 树的模拟页面直观地体验算法过程
插入
当插入某个键后发现节点溢出了,就要分裂节点:
删除
当删除某个键后发现节点不足,就要4:
- 尝试节点重平衡;
- 如果平衡失败,递归地合并节点
尝试节点重平衡(try rebalancing):
- 如果有左邻居,检查左邻居节点是否有多余的键:
- 如果有,弹出最大的键替换父节点的键,而把原父节点的键插入到目标节点,分配成功;
- 否则,继续检查
- 如果有右邻居,检查右邻居节点是否有多余的键:
- 如果有,弹出最小的键替换父节点的键,而把原父节点的键插入到目标节点,分配成功;
- 否则,重平衡失败
下图假设了一个 $m=3$ 的 B 树删除情况,空白节点是被删除的 $4$ :
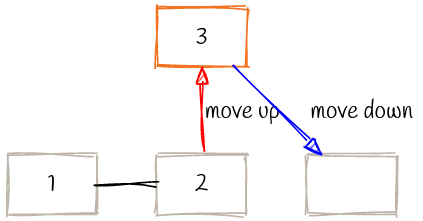
之后情况变为如下所示:
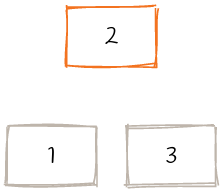
递归地合并节点:
实现->数据结构
辅助宏
就像前文二叉搜索树那样,我们首先通过一个宏,来描述这个系列的 B 树的代码结构,来避免无谓的重复8:
其中 M 表示阶数,这也暗示我们的节点将不再像二叉搜索树那样在字段名上分出键和孩子的顺序,而是采用更一般化地安排。
macro_rules! impl_tree {
(
$(#[$attr:meta])*
$treename:ident {
$(
$(#[$field_attr:meta])*
$name: ident : $ty: ty
),*
}
) =>
{
$(#[$attr])*
pub struct $treename<K, V, const M: usize> {
root: Node<K, V>,
/* extra attr */
$(
$(#[$field_attr])*
$name: $ty
),*
}
impl<K, V, const M: usize> $treename<K, V, M> {
const fn entries_low_bound() -> usize {
M.div_ceil(2) - 1
}
const fn entries_high_bound() -> usize {
M
}
}
};
}
节点包装 Node<K, V> 沿用二叉搜索树里的实现。
而我对属性访问相关的宏 attr 和 def_attr_macro ,为了更加丰富的功能和完整一致的语义而进行了重构:
/// Evil hack for Rc<RefCell<T>>
#[macro_export]
macro_rules! attr {
(ref_mut | $node:expr, $attr:ident, $ty:ty) => { {
if let Some(_unr) = $node.clone().0 {
let _bor = _unr.as_ref().borrow();
let _attr = (&_bor.$attr) as *const $ty as *mut $ty;
drop(_bor);
unsafe { &mut *_attr }
}
else {
panic!("Access {} on None", stringify!($attr));
}
} };
(ref | $node:expr, $attr:ident, $ty:ty) => { {
if let Some(_unr) = $node.clone().0 {
let _bor = _unr.as_ref().borrow();
let _attr = (&_bor.$attr) as *const $ty;
drop(_bor);
unsafe { &*_attr }
}
else {
panic!("Access {} on None", stringify!($attr));
}
} };
(clone | $node:expr, $attr:ident) => { {
if let Some(_unr) = $node.clone().0 {
let _bor = _unr.as_ref().borrow();
let _attr = _bor.$attr.clone();
drop(_bor);
_attr
}
else {
panic!("Access {} on None", stringify!($attr));
}
} };
(self | $node:expr) => { {
if let Some(_unr) = $node.clone().0 {
unsafe { &* _unr.as_ref().as_ptr() }
}
else {
panic!("Call {} on None", stringify!($attr));
}
} };
(self_mut | $node:expr) => { {
if let Some(_unr) = $node.clone().0 {
unsafe { &mut * _unr.as_ref().as_ptr() }
}
else {
panic!("Call {} on None", stringify!($attr));
}
} };
($node:expr, $attr:ident, $val:expr) => { {
if let Some(bor) = $node.clone().0 {
bor.as_ref().borrow_mut().$attr = $val
}
else {
panic!("MAccess {} on None", stringify!($attr));
}
} };
}
#[macro_export]
macro_rules! def_attr_macro {
(ref | $(($name:ident,$ty:ty)),+) => {
$(
macro_rules! $name {
($node:expr) => {
attr!(ref | $$node, $name, $ty)
};
($node:expr, $val:expr) => {
attr!($$node, $name, $$val)
};
}
#[allow(unused)]
pub(crate) use $name;
coll::paste!(
#[allow(unused)]
macro_rules! [<$name _mut>] {
($node:expr) => {
attr!(ref_mut | $$node, $name, $ty)
};
}
#[allow(unused)]
pub(crate) use [<$name _mut>];
);
)+
};
(clone | $($name:ident),+) => {
$(
macro_rules! $name {
($node:expr) => {
attr!(clone | $$node, $name)
};
($node:expr, $val:expr) => {
attr!($$node, $name, $$val)
};
}
#[allow(unused)]
pub(crate) use $name;
)+
}
}
B-树结构
impl_tree!(
/// B-Trees
///
/// Panic: M > 2
///
/// Recommend: maybe 60, 90, 250
/// (Rust use M=12 (B=6, M=2B-1+1) maybe increase it in the futer)
#[derive(Debug)]
BT {}
);
B-树节点
前面都是公共的代码,而对于真正节点的定义 Node_ 的定义是真正独特设计的体现,这里有两点需要注意的:
- 普通的 B 树就像二叉搜索树一样直接把键值存在一起,这里用
KVEntry把它们直接放到一起便于集中管理,KVEntry是一个以第一个元素为排序键的二元组。 - 对节点内键的存储使用了连续地址的向量结构,这是我在实现时的第一选择,在经典的 CPU 架构下,这样不超过 $100$ 个 指针宽度的数组的读写是最优的9
impl_node!();
def_attr_macro!(clone|
paren
);
def_attr_macro!(ref|
(entries, Vec<KVEntry<K, V>>),
(children, Vec<Node<K, V>>)
);
struct Node_<K, V> {
entries: Vec<KVEntry<K, V>>,
/// 即使是叶子节点,也要保持孩子数量 = k-v 数量 + 1
children: Vec<Node<K, V>>,
paren: WeakNode<K, V>
}
KVEntry
#[derive(Debug, Clone)]
pub struct KVEntry<K, V>(pub K, pub V);
impl<K, V> KVEntry<K, V> {
pub fn drain(self) -> (K, V) {
(self.0, self.1)
}
}
impl<K: PartialEq, V> PartialEq for KVEntry<K, V> {
fn eq(&self, other: &Self) -> bool {
self.0 == other.0
}
}
impl<K: PartialOrd, V> PartialOrd for KVEntry<K, V> {
fn partial_cmp(&self, other: &Self) -> Option<Ordering> {
self.0.partial_cmp(&other.0)
}
}
impl<K: Eq, V> Eq for KVEntry<K, V> {}
impl<K: Ord, V> Ord for KVEntry<K, V> {
fn cmp(&self, other: &Self) -> Ordering {
self.partial_cmp(&other).unwrap()
}
}
实现->基础方法
如果是从二叉搜索树第一次接触到 B 树这样的 $m$ 路搜索树($m \geqslant 3$),会感到很多观念上的不适应,一些基础操作到底怎么实现,难以想得很清楚10。
一个关键的区别在于二叉搜索树一个节点只有一个键,在这种情况下,键就是节点,节点就是键,找到了节点就找到了键,反之亦然。
而 B 树这样的多路搜索树不止有一个键,找到了节点后还要在节点里寻找键,不仅考虑得是节点间的关系,还要考虑节点内键之间的关系,以及某个键的对应的左右孩子的索引位置。
因此这里我们首先要点出键和孩子在节点内的布局。
节点布局
- 对于键,按向量的地址增长顺序从小到大排列;
- 对于孩子,也按照同样地顺序排列
这样有 $\text{len(keys) + 1 = len(children)}$ ,并且节点内索引为 $i$ 的键对应的左右孩子分别为 $\text{children}[i]$ 和 $\text{children}[i+1]$ 。
也就是说,与孩子同编号的是右邻居键,每个键与它的左孩子同编号:
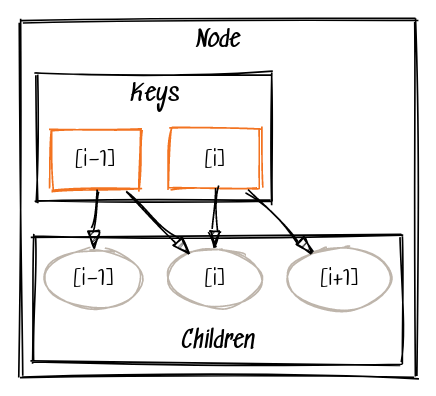
创建节点
我们同样可以使用二叉搜索树那里用过的 node 宏来简化节点的创建。
创建新节点的情景有两种:
- 树为空的时候,从新开始创建一个叶子节点,这时只需要指明键值对儿即可;
- 节点分裂以及
push_new_level的时候,这时需要指明节点的各个属性
use coll::{ *, node as aux_node };
// ...
macro_rules! node {
(kv| $k:expr, $v:expr) => { {
// overflow is M
let mut entries = Vec::with_capacity(M);
entries.push(KVEntry($k, $v));
let children = vec![Node::none() ; 2];
node!(basic| entries, children, WeakNode::none())
} };
(basic| $entries:expr, $children:expr, $paren:expr) => { {
aux_node!(FREE {
entries: $entries,
children: $children,
paren: $paren
})
} };
}
求取子节点索引
在二叉搜索树的系列里常用到一个给出子节点,求它是父节点的左孩子还是右孩子的操作,使用这个 index_of_child 宏。
在 B 树上更有这样需求,不管是获取键还是孩子。
最普遍性的方法是遍历父节点的孩子索引:
显然它的时间复杂度是线性的,是 $O(m)$
/// O(M)
macro_rules! index_of_child_by_rc {
($p: expr, $child: expr) => { {
let p = &$p;
let child = &$child;
debug_assert!(child.is_some());
if let Some(idx) = children!(p).iter().position(|x| x.rc_eq(child)) {
idx
}
else {
panic!("There are no matched child");
}
} };
}
虽然 $m$ 也不会很大,但是线性时间复杂度显然有改进的余地。
我们可以直接通过利用孩子节点里任一一个键在父节点上执行二分查找:
时间复杂度就变成对数级的,是 $O(\text{log}\ m)$
/// O(logM) search by key
macro_rules! index_of_child {
($p: expr, $child: expr) => { {
let p = &$p;
let child = &$child;
debug_assert!(child.is_some());
match entries!(p).binary_search(child.last_entry()) {
Ok(oldidx) => {
panic!("Dup key on {oldidx}");
},
Err(inseridx) => {
inseridx
},
}
} };
}
impl<K, V> Node<K, V> {
#[track_caller]
fn last_entry(&self) -> &KVEntry<K, V> {
if let Some(ent) = entries!(self).last() {
ent
}
else {
panic!("EMPTY entries");
}
}
}
但是这个方法存在限制,无法适用于空节点的情况,在删除键的一些情境下只能回归到普遍性的算法上。
搜索到叶子节点
impl<K, V> Node<K, V> {
/// 漂亮的尾递归
fn search<Q>(&self, k: &Q) -> Option<(Self, usize)>
where K: Borrow<Q>, Q: Ord + ?Sized
{
if self.is_some() {
match entries!(self).binary_search_by_key(&k, |ent| ent.0.borrow()) {
Ok(idx) => Some((self.clone(), idx)),
Err(idx) => children!(self)[idx].search(k),
}
}
else {
None
}
}
}
实现->一般公开方法
impl<K: Ord, V, const M: usize> BT<K, V, M> {
pub fn new() -> Self {
assert!(M > 2, "M should be greater than 2");
Self { root: Node::none() }
}
pub fn get<Q>(&self, k: &Q) -> Option<&V>
where K: Borrow<Q>, Q: Ord + ?Sized
{
self
.root
.search(k)
.map(|(node, idx)| &entries!(node)[idx].1)
}
pub fn get_mut<Q>(&mut self, k: &Q) -> Option<&mut V>
where K: Borrow<Q>, Q: Ord + ?Sized
{
self
.root
.search(k)
.map(|(node, idx)| &mut entries_mut!(node)[idx].1)
}
}
实现->插入方法
搜索、插入
这个插入的主流程和二叉搜索树的插入结构上是类似的。
impl<K: Ord, V, const M: usize> BT<K, V, M> {
pub fn insert(&mut self, k: K, v: V) -> Option<V> {
let mut y = &Node::none();
let mut x = &self.root;
let mut idx = 0;
while x.is_some() {
match entries!(x).binary_search_by_key(&&k, |ent| &ent.0) {
Ok(idx_) => {
idx = idx_;
break;
},
Err(idx_) => {
idx = idx_;
y = x;
x = &children!(y)[idx];
},
}
}
if x.is_some() {
return Some(
replace(&mut entries_mut!(x)[idx].1, v)
);
}
if y.is_none() {
self.root = node!(kv| k, v);
}
else {
/* insert into leaf */
entries_mut!(y).insert(idx, KVEntry(k, v));
children_mut!(y).push(Node::none());
if entries!(y).len() == M {
self.promote(y.clone());
}
}
None
}
}
节点提升
Rust 标准库里的 Vec 为我们提供了一切的便利方法,从二分查找到向量分割(split_off)。不过与其说是 Rust 为我们提供了便利,不如说是它的 API 设计指导了我们的代码风格。
回顾之前的节点提升的算法,对比下这里的代码实现:
分离节点
- 目标节点的键值按照 $\lceil {\large\frac{m}{2}}\rceil$ 分出右半部分,左半部分弹出尾部的键值作为提升;
- 目标节点的孩子按照 $\lceil {\large\frac{m}{2}}\rceil$ 分出右半部分,把分出的这些键值和孩子组合成新的右邻居节点;
- 不要忘记更新新节点的孩子的反向引用指向自己
检查是否停止
- 如果到达根节点,把提升的键值,和分裂出的两个孩子组合成新的根节点;
- 否则把提升的键值和右邻节点插入到对应的父节点中,检查父节点是否溢出,递归地进行提升
impl<K: Ord, V, const M: usize> BT<K, V, M> {
/// 漂亮的尾递归
fn promote(&mut self, x: Node<K, V>) {
debug_assert_eq!(entries!(x).len(), Self::entries_high_bound());
/* split node */
let split_pos = M.div_ceil(2);
let entries_x = entries_mut!(x);
let entries_x2 = entries_x.split_off(split_pos);
let entry_head = entries_x.pop().unwrap();
let children_x2 = children_mut!(x).split_off(split_pos);
let x2 = node!(basic| entries_x2, children_x2, WeakNode::none());
children_revref!(x2);
let p = paren!(x).upgrade();
if p.is_none() {
/* push new level */
let entries = vec![entry_head];
let children = vec![x, x2];
self.root = node!(basic| entries, children, WeakNode::none());
children_revref!(self.root);
}
else {
/* insert into paren node */
let x_idx = index_of_child!(p, x);
entries_mut!(p).insert(x_idx, entry_head);
children_mut!(p).insert(x_idx + 1, x2.clone());
paren!(x2, p.downgrade());
if entries!(p).len() == Self::entries_high_bound() {
self.promote(p);
}
}
}
}
macro_rules! children_revref {
($x:expr) => {
{
let x = &$x;
let children = children_mut!(x);
if children[0].is_some() {
for child in children {
paren!(child, x.downgrade());
}
}
}
};
}
实现->删除方法
搜索、删除
删除的主流程,同样类似于二叉搜索树的算法,找到目标键,和后继键交换,确保最终要删除的键位于叶子节点。
impl<K: Ord, V, const M: usize> BT<K, V, M> {
pub fn remove<Q>(&mut self, k: &Q) -> Option<V>
where K: Borrow<Q> + Debug, Q: Ord + ?Sized, V: Debug
{
if let Some((mut x, mut idx)) = self.root.search(k) {
/* Swap with its successor leaf node */
if children!(x)[0].is_some() {
let (succ, succ_idx) = children!(x)[idx+1].minimum();
swap(
&mut entries_mut!(x)[idx],
&mut entries_mut!(succ)[succ_idx],
);
x = succ;
idx = succ_idx;
}
debug_assert!(children!(x)[0].is_none());
let popped = entries_mut!(x).remove(idx);
children_mut!(x).pop();
if entries!(x).is_empty() {
if paren!(x).is_none() {
self.root = Node::none();
}
else {
self.unpromote(x);
}
}
Some(popped.1)
}
else {
None
}
}
}
impl<K, V> Node<K, V> {
/// Left most
fn minimum(&self) -> (Self, usize) {
let mut x = self;
let mut y = Node::none();
while x.is_some() {
y = x.clone();
x = children!(x).first().unwrap();
}
(y, 0)
}
}
节点下沉
impl<K: Ord, V, const M: usize> BT<K, V, M> {
fn unpromote(&mut self, x: Node<K, V>) {
// Exclude leaf node
debug_assert!(
children!(x)[0].is_none()
|| entries!(x).len() == Self::entries_low_bound() - 1
);
if let Err((p, idx)) = self.try_rebalancing(&x) {
/* merge with sib node (rebalance failed means that each node are small) */
// merge left child
if idx > 0 {
entries_mut!(x).insert(0, entries_mut!(p).remove(idx - 1));
merge_node!(p, idx - 1);
}
// merge right child
else {
entries_mut!(x).push(entries_mut!(p).remove(0));
merge_node!(p, idx);
}
if paren!(p).is_none() {
// pop new level
if entries!(p).is_empty() {
debug_assert!(children!(p)[0].is_some());
debug_assert_eq!(children!(p).len(), 1);
self.root = children_mut!(p).pop().unwrap();
paren!(self.root, WeakNode::none());
}
} else {
if entries!(p).len() < Self::entries_low_bound() {
self.unpromote(p);
}
}
}
}
}
尝试重平衡
这里使用了二叉搜索树里定义的 Dir 枚举结构,提供方向标识。
对节点的重平衡当初是用宏来描述的,但完全可以替换成一般的方法。
use crate::bst::{Left, Right};
impl<K: Ord, V, const M: usize> BT<K, V, M> {
fn try_rebalancing(&mut self, x: &Node<K, V>)
-> std::result::Result<(), (Node<K, V>, usize)>
{
debug_assert!(paren!(x).is_some());
let p = paren!(x).upgrade();
let idx = index_of_child_by_rc!(p, x);
/* Check if siblings has remains */
if idx > 0 {
try_node_redistribution!(p, idx-1, Left);
}
if idx < children!(p).len() - 1 {
try_node_redistribution!(p, idx, Right);
}
Err((p, idx))
}
}
/// (parent, left-idx, sib_dir)
macro_rules! try_node_redistribution {
($p:expr, $idx:expr, $sib_dir:expr) => { {
let p = &$p;
let idx = $idx;
let sib_dir = $sib_dir;
let children = children!(p);
let left = &children[idx];
let right = &children[idx+1];
let sib = if sib_dir.is_left() { left } else { right };
if children!(sib)[0].is_none() && entries!(sib).len() > 1
|| entries!(sib).len() > Self::entries_low_bound()
{
if sib_dir.is_left() {
entries_mut!(right).insert(
0,
replace(
&mut entries_mut!(p)[idx],
entries_mut!(left).pop().unwrap()
)
);
let child = children_mut!(left).pop().unwrap();
if child.is_some() {
paren!(child, right.downgrade());
}
children_mut!(right).insert(
0,
child
);
}
else {
entries_mut!(left).push(
replace(
&mut entries_mut!(p)[idx],
entries_mut!(right).remove(0)
)
);
let child = children_mut!(right).remove(0);
if child.is_some() {
paren!(child, left.downgrade());
}
children_mut!(left).push(
child
);
}
return Ok(())
}
} }
}
合并节点
/// (parent, left-idx)
macro_rules! merge_node {
($p:expr, $idx:expr) => { {
let p = &$p;
let idx = $idx;
let children = children!(p);
let left = children[idx].clone();
let right = children[idx + 1].clone();
// merge right's children to the left
let left_children = children_mut!(left);
for child in children_mut!(right).drain(..) {
if child.is_some() {
paren!(child, left.downgrade());
}
left_children.push(child);
}
// merge entries
entries_mut!(left).extend(entries_mut!(right).drain(..));
// remove right from p
children_mut!(p).remove(idx + 1);
} };
}
实现->测试方法
这里介绍了测试与调试相关的代码
打印节点
macro_rules! key {
($x:expr, $idx:expr) => {
&entries!($x)[$idx].0
};
}
impl<K: Debug, V> Debug for Node<K, V> {
fn fmt(&self, f: &mut Formatter<'_>) -> Result {
if self.is_some() {
let kn = entries!(self).len();
for i in 0..kn - 1 {
write!(f, "{:?}, ", key!(self, i))?;
}
write!(f, "{:?}", key!(self, kn - 1))?;
} else {
write!(f, "nil")?;
}
Ok(())
}
}
打印树
impl<K: Ord, V, const M: usize> BT<K, V, M> {
fn debug_write<W: std::fmt::Write>(
&self,
f: &mut W,
) -> std::fmt::Result
where
K: std::fmt::Debug,
V: std::fmt::Debug,
{
use common::vecdeq;
/* print header */
writeln!(f, "{self:?}")?;
/* print body */
if self.root.is_none() {
return Ok(());
}
let mut this_q = vecdeq![vec![self.root.clone()]];
let mut lv = 1;
while !this_q.is_empty() {
writeln!(f)?;
writeln!(f, "############ Level: {lv} #############")?;
writeln!(f)?;
let mut nxt_q = vecdeq![];
while let Some(children) = this_q.pop_front() {
for (i, x) in children.iter().enumerate() {
let p = paren!(x).upgrade();
if x.is_some() && children!(x)[0].is_some() {
nxt_q.push_back(children!(x).clone());
}
writeln!(f, "({i:02}): {x:?} (p: {p:?})")?;
}
writeln!(f)?;
}
this_q = nxt_q;
lv += 1;
}
writeln!(f, "------------- end --------------\n")?;
Ok(())
}
fn debug_print(&self)
where
K: std::fmt::Debug,
V: std::fmt::Debug,
{
let mut cache = String::new();
self.debug_write(&mut cache).unwrap();
println!("{cache}")
}
}
性质校验
impl<K: Ord, V, const M: usize> BT<K, V, M> {
fn validate(&self)
where
K: Debug
{
if self.root.is_none() {
return;
}
use std::collections::VecDeque;
use common::vecdeq;
let mut cur_q = vecdeq![vecdeq![Node::none(), self.root.clone()]];
while !cur_q.is_empty() {
let mut nxt_q = vecdeq![];
let mut leaf_num = 0;
let mut internal_num = 0;
while let Some(mut group) = cur_q.pop_front() {
let p = group.pop_front().unwrap();
for child in group.iter() {
assert!(child.is_some());
assert_eq!(
entries!(child).len() + 1,
children!(child).len(),
"{child:?}"
);
assert!(
children!(child).len() <= M,
"{child:?}: {}",
children!(child).len()
);
assert!(
entries!(child).len() < Self::entries_high_bound()
);
// Exclude leaf
if children!(child)[0].is_none() {
assert!(entries!(child).len() > 0);
leaf_num += 1;
} else {
// Exclude the root (which is always one when it's internal node)
if paren!(child).is_some() {
assert!(
entries!(child).len()
>= Self::entries_low_bound()
);
} else {
assert!(children!(child).len() >= 2);
}
internal_num += 1;
let mut nxt_children =
VecDeque::from(children!(child).clone());
nxt_children.push_front(child.clone());
nxt_q.push_back(nxt_children);
}
}
// All leaves are in same level
assert!(
leaf_num == 0 || internal_num == 0,
"leaf: {leaf_num}, internal: {internal_num}"
);
// Ordered
if p.is_some() {
let last_child = group.pop_back().unwrap();
for (i, child) in group.iter().enumerate() {
assert!(entries!(child).is_sorted());
let child_max_key = &child.last_entry().0;
let branch_key = key!(p, i);
assert!(
child_max_key < branch_key,
"child: {child_max_key:?}, branch:{branch_key:?}"
);
}
assert!(key!(last_child, 0) > &p.last_entry().0);
}
}
cur_q = nxt_q;
}
}
}